Concepts
Tables
Tables represent the location and, optionally, the column types of a SQL Database table. They are used in most Astro SDK tasks and decorators.
There are two types of tables:
Persistent Table
These are tables that are of some importance to users and will we persist in a database even after a DAG run is finished and won’t be deleted by When to use the cleanup operator. Users can still drop them by using drop table operator. You can create these tables by passing in a
nameparameter while creating aastro.sql.table.Tableobject.output_table=Table(name="expected_table_from_s3", conn_id="postgres_conn"),
Temporary Tables
It is a common pattern to create intermediate tables during a workflow that don’t need to be persisted afterwards. To accomplish this, users can use Temporary Tables in conjunction with the When to use the cleanup operator task.
There are two approaches to create temporary tables:
Explicit: instantiate a
astro.sql.table.Tableusing the argument temp=TrueImplicit: instantiate a
astro.sql.table.Tablewithout giving it a name, and without specifying the temp argumentoutput_table=Table( conn_id="postgres_conn", ),
Metadata
Metadata is used to give additional information to access a SQL Table.
For example, a user can detail the Snowflake schema and database for a table, whereas a BigQuery user can specify the namespace and dataset. Although these parameters can change name depending on the database, we have normalised the Metadata class to name their schema and database.
input_table_2 = Table(
name="ADOPTION_CENTER_2_" + str(int(time.time())),
metadata=Metadata(
database=os.environ["SNOWFLAKE_DATABASE"],
schema=os.environ["SNOWFLAKE_SCHEMA"],
),
conn_id="snowflake_conn",
temp=True,
)
How load_file Works
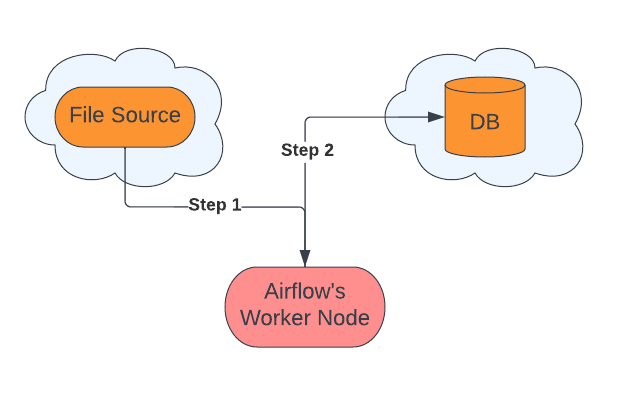
When we load a file located in cloud storage to a cloud database, internally the steps involved are:
Steps:
Get the file data in chunks from file storage to the worker node.
Send data to the cloud database from the worker node.
This is the default way of loading data into a table. There are performance bottlenecks because of limitations of memory, processing power, and internet bandwidth of worker node.
Improving bottlenecks by using native transfer
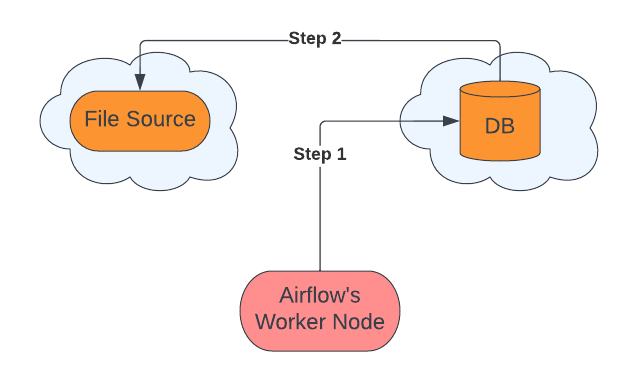
Some of the cloud databases like Bigquery and Snowflake support native transfer (complete list of supported native transfers Supported native transfers) to ingest data from cloud storage directly. Using this we can ingest data much quicker and without any involvement of the worker node.
Steps:
Request destination database to ingest data from the file source.
Database request file source for data.
This is a faster way for datasets of larger size as there is only one network call involved and usually the bandwidth between vendors is high. Also, there is no requirement for memory/processing power of the worker node, since data never gets on the node. There is significant performance improvement due to native transfers as evident from benchmarking results.
Note - By default the native transfer is enabled and will be used if the source and destination support it, this behavior can be altered by the use_native_support param.
Templating
Templating is a powerful concept in Airflow to pass dynamic information into task instances at runtime. Templating in Airflow works exactly the same as templating with Jinja in Python: define your to-be-evaluated code between double curly braces, and the expression will be evaluated at runtime.
The parameter list passed to the decorated function is also added to the context which is used to render template. For example:
@aql.transform
def union_top_and_last(first_table: Table, second_table: Table): # skipcq: PYL-W0613
"""Union `first_table` and `second_table` tables to create a simple dataset."""
return """
SELECT title, rating from {{first_table}}
UNION
SELECT title, rating from {{second_table}};
"""
More details can be found at Airflow’s Templates reference.
Patterns in File path
We also resolve the patterns in file path based on the Supported File Location
Local - Resolves
File.pathusing the glob standard library (https://docs.python.org/3/library/glob.html)S3 - Resolves
File.pathusing AWS S3 prefix rules (https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-prefixes.html)GCS - Resolves
File.pathusing Google Cloud Storage (GCS) wildcard rules (https://cloud.google.com/storage/docs/gsutil/addlhelp/WildcardNames)
Datasets
An Airflow dataset is a stand-in for a logical grouping of data. Datasets may be updated by upstream “producer” tasks, and dataset updates contribute to scheduling downstream “consumer” DAGs.
A dataset is defined by a Uniform Resource Identifier (URI):
from airflow import Dataset
example_dataset = Dataset("s3://dataset-bucket/example.csv")
Astro SDK uses following URIs as datasets across its operators.
Tables as a Dataset
imdb_movies_table = Table(name="imdb_movies", conn_id="postgres_conn")
File as a Dataset
input_file = File(path="https://raw.githubusercontent.com/astronomer/astro-sdk/main/tests/data/imdb_v2.csv")
Following examples show how to produce and use datasets for scheduling.
Dataset Producer - Produces output dataset
imdb_movies_tableas a Table.with DAG( dag_id="example_dataset_producer", schedule=None, start_date=START_DATE, catchup=False, ) as load_dag: imdb_movies = aql.load_file( input_file=input_file, task_id="load_csv", output_table=imdb_movies_table, )
Dataset Consumer - DAG gets scheduled post input dataset Table
imdb_movies_tableis produced by the upstream DAG above.with DAG( dag_id="example_dataset_consumer", schedule=[imdb_movies_table], start_date=START_DATE, catchup=False, default_args=default_args, ) as transform_dag: top_five_animations = get_top_five_animations( input_table=imdb_movies_table, output_table=top_animations_table, )
Python SDK uses default datasets for its operators and the details of the default datasets generated and used by them can be found in the respective Operators document.
However, you can override them by passing the keyword arguments inlets and outlets to the operators.
You can disable the usage of these default datasets and hence disable data-aware scheduling of DAGs by updating Airflow’s configuration in airflow.cfg
[astro_sdk]
auto_add_inlets_outlets = "false"
or by setting the below environment variable in your deployment
AIRFLOW__ASTRO_SDK__AUTO_ADD_INLETS_OUTLETS = "false"
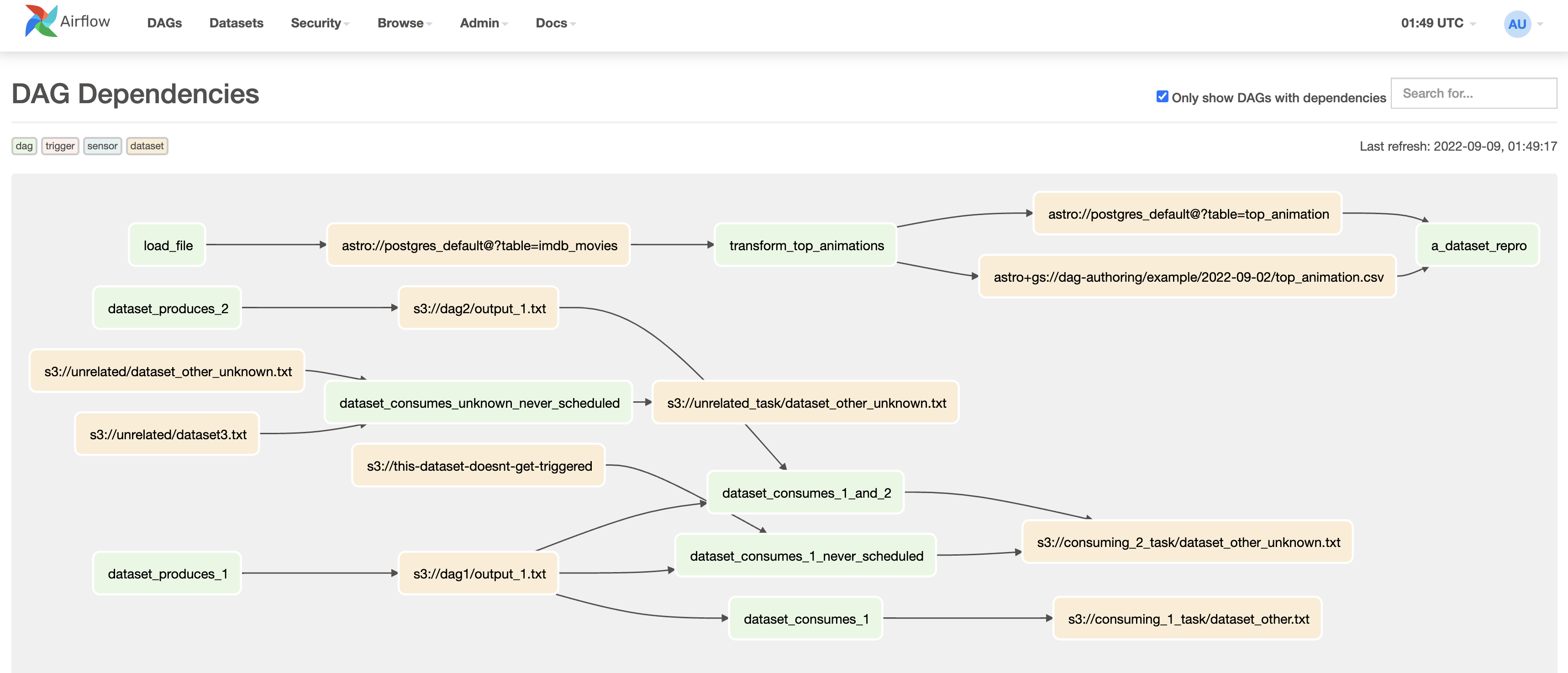
Following is a view of dag dependencies on datasets
More details can be found at Airflow’s Dynamic Task Mapping.
Note
The concept of Datasets in astro-sdk is supported only from the 1.1.0 release ( and requires Airflow version 2.4.0 and above).